The Hook
Consider being given a brush and instructed to draw a "tree" on a canvas. Most likely, you would first picture a tree that you have seen before and then draw it. But what if you were asked to depict more abstract notions such as "landscape", "human", "self", or "world"? What would you draw if I extended this mental exercise to include prompts like "Tokyo night with purple sky"?
In this post, we discuss language-derived image generation, a subfield of computational creativity, and how modern evolutionary algorithms such as evolutionary strategy (ES) can be used to synthesis attractive minimalist style artworks based on abstract word prompts.

Introduction
Recently I came upon an intriguing workshop paper by Yingtao Tian and David Ha, both were research scientists at Google Brain Tokyo by the time the paper was published in 2021, the same year DALLE was created. Since then, Ha has moved on to join Sakana AI, a Tokyo-based AI research lab focusing on developing a new foundation model architecture based on collective intelligence, which is another interesting topic if you read Ha’s blog.
In summary, the paper demonstrate a unique art style when using SOTA evolutionary strategy algorithm to fit geometric primitive shapes like semi-transparent triangles to be as similar as to either concrete images or abstract concepts. In this review I will focus on the more interesting part which is fitting abstract concepts from text to image. However if you would like a quick taste of the how fitting concrete images looks like in practice, here is a simple demo built by AlteredQualia, which is a reimplementation of Roger Johansson’s idea trace all the way back to 2008.
I was also interested in exploring the use of evolutionary algorithms (mostly because it sounds really cool) as an alternative for optimization problems to gradient-based algorithms like Adam (2014).
This post is organized into three parts:
- Part I: problem formulation
- We talk about the high-level architecture of the proposed method
- Part II: CLIP
- We provide more context around CLIP and its multimodal embedding space pretraining.
- Part III: demo
- We validate the proposed method by reproducing paper’s result
Finally we wrap everything up with a few short & sweet takeaways.
Key Concepts
- Evolutionary algorithms: a class of optimization algorithms. Under this we have three main streams
- Genetic algorithms (GA)
- Evolution strategies (ES)
- Evolutionary programming (EP)
- CLIP (Contrastive Language-Image Pre-Training): a neural network trained on a variety of (image, text) pairs, created by OpenAI.
- Cubism Art Movement: an avant-garde art movement originate in the early 20th century. It was invented by artists Pablo Picasso and Georges Braque.

Part I: Problem formulation
On a high level it’s a simple problem to formulate despite of its multimodal nature. Here are the steps took:
- Choose a parameter space: choose a set of parameters to optimize.
- Random initialization: randomly initialize N triangle’s parameters.
- Render the parameters: we would need to create a renderer class to render raw parameters (i.e. an array of numbers) on a digital canvas for demo and debugging purpose.
- Optimize parameters: use ES to optimize parameters such that they minimize or maximize the chosen fitness function.
- Repeat from step 3 for K iterations.
A few design decisions are involved in this work:
- Choice of parameter space
- Here the authors chose for each of the triangles, which include the three vertex coordinates and the RGBA (Red, Green, Blue, and Alpha a.k.a. transparency channel) color. If we initialize N triangles then we will have 10N parameters.
- The ES algorithm can use the number of triangles N as an upper limit and chooses to use fewer triangles by setting some triangles’ alpha to zero.
- Choice of evolutionary algorithm
- The authors chose a by-then state-of-the-art evolution strategy (ES), PGPE with ClipUp.
- Choice of fitness function
- For fitting abstract concepts, they used cosine loss between the generated image embeddings (encoded with CLIP image encoder) and text prompt (encoded with CLIP text encoder).
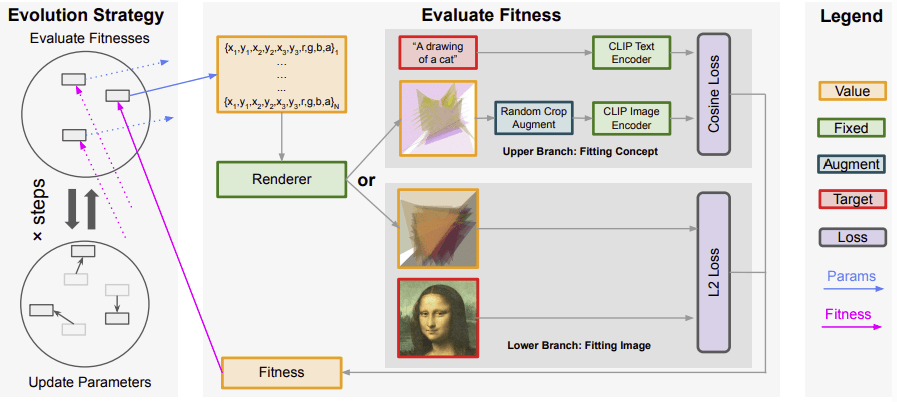
In the above figure, the parameters are rendered onto a canvas first before the method calculates the fitness as a loss to guide the evolutionary algorithm. We focus on the upper part of the fitness evaluation pipeline.
Part II: CLIP (Contrastive Language-Image Pre-training)
One key component of fitting abstract concepts to images is CLIP, a pretrained multimodal neural net by OpenAI that is able to encode images and text into a shared embedding space. CLIP was motivated by some major challenges in image classification using deep neural networks, like:
- Labor-intensive process to generate good-quality image classification datasets
- Trained models perform poorly for labels not in the datasets, leading to poor real-world performance and generalization.
- Models often perform well on benchmarks but have disappointingly poor performance on stress tests.
The impact was profound, as the researchers were able to demonstrate CLIP’s zero-shot ability to classify unseen image objects, beating the SOTAs in multiple image benchmarks without any finetuning on the benchmark images. A critical insight that differentiated CLIP’s training methodology, quoted from OpenAI’s blog, was to “leverage natural language as a flexible prediction space to enable generalization and transfer.”.
PS: As I’m writing this post, I noticed it’s been three years since OpenAI published its blog on CLIP. I’m just amazed by the progress AI has made over the last three years.
Architecture
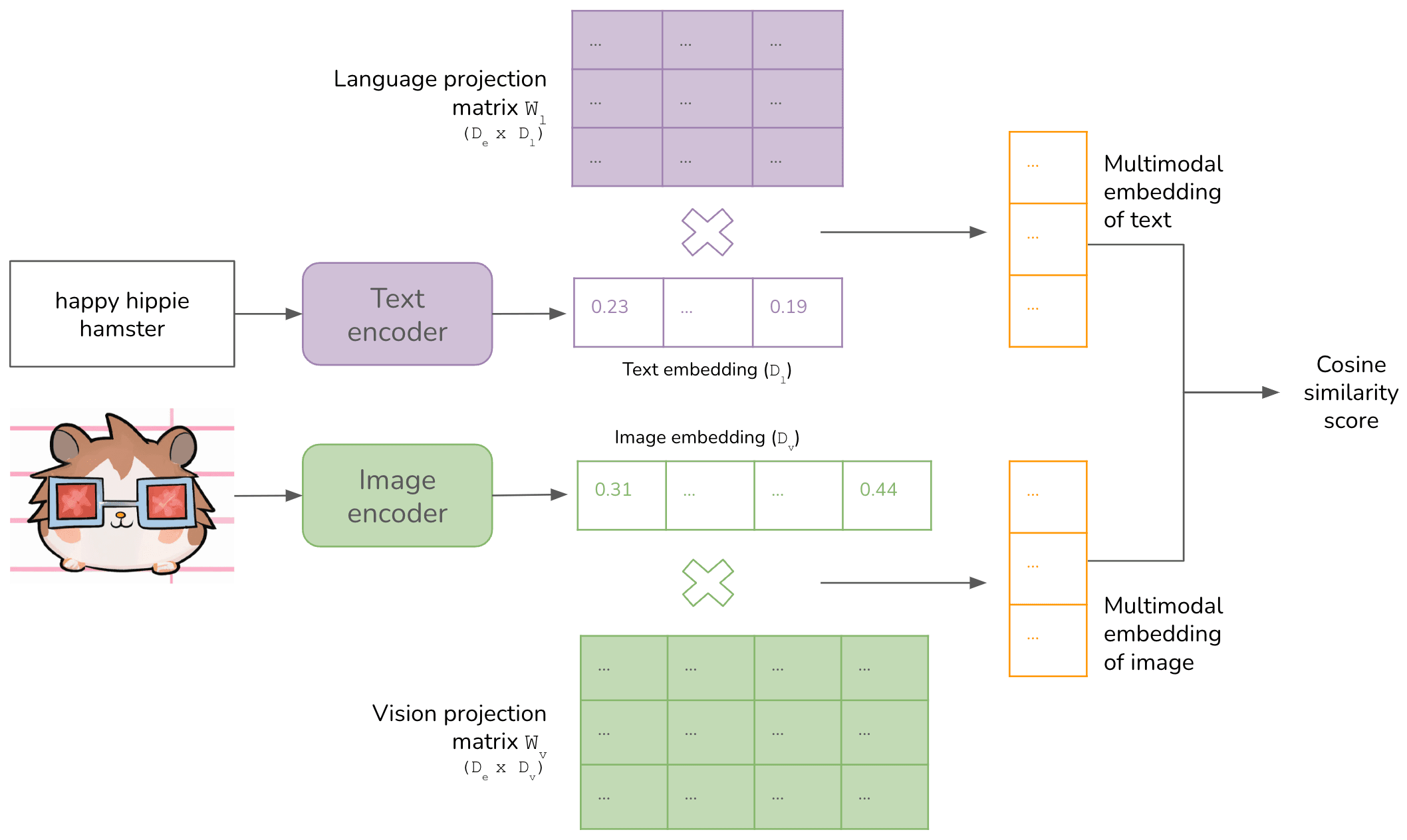
Although CLIP is not directly motivated by image generation, the authors innovatively used its image and text encoders to fit natural language prompts into minimalist paintings. At a high level, CLIP consists of the following components:
- An image encoder and a text encoder to generate the embeddings for data for that modality.
- A way to align embeddings of different modalities into the same multimodal embedding space.
Part III: Demo
In this part, I reproduce the authors’ results on my local machine. Here are the demo artworks and their prompts that I thought were really interesting. I run the ES algorithm with one GPU for 10,000 iterations with 50 triangles and a population size of 256. On average, it took 3 hours to fit each prompt.
Here’s the bash script used:
#!/bin/bash
# Define an array of prompt arguments
prompts=("Brain", "Chinese New Year", "Mars Colony", "The Great Wave off Kanagawa", "Family", "Tokyo night with purple sky", "World", "Self")
triangles=(50)
# Loop through the array and execute the command with each prompt argument
for prompt in "${prompts[@]}"
do
for triangle in "${triangles[@]}"
do
python3 ./es_clip.py --prompt $prompt --n_triangle 50 --n_iterations 10000 --gpus 1 --report_interval 100 --step_report_interval 100 --save_as_gif_interval 100
done
done

We see some results that were similar compared to the original paper (e.g. “self”), while having some other creative result. My personal favorite is “Mars Colony." The generated painting actually looked like a Mars lander with some support structure beneath it.
Takeaways
- Evolutionary algorithms are often considered slower compared with gradient-based algorithms. The authors demonstrated that modern evolution strategies (ES) algorithms can be combined with drawing primitives of triangles inspired by the minimalism art style.
- Gradient-based methods are usually more domain-specific, while ES is agnostic to the domain.
- “ES is agnostic to the domain, i.e., how the renderer works. We envision that ES-inspired approaches could potentially unify various domains with significantly less effort for adaption in the future.” (Tian and Ha, 2022, p. 11)